ELK日志搜集查询
ELK是三个软件的缩写,ElasticSearch、LogStash和Kibana。简单来说,LogStash负责搜集过滤,ElasticSearch负责存储和搜索,Kibana负责展示。
一、logstash
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
1.1 logstash安装
logstash-5.1.1.zip
unzip logstash-5.1.1.zip
./logstash-5.1.1/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
输入 hello world 回车,出现下面json,说明正常。
{
"@timestamp" => 2016-12-24T04:33:08.670Z,
"@version" => "1",
"host" => "bogon",
"message" => "hello world",
"tags" => []
}
bin/logstash -f /etc/logstash.d/ 指定目录或者文件
后台启动
- init.d
- nohup &
- supervisord supervisord 配置示例
[program:elk_l]
environment=LS_HEAP_SIZE=5000m
directory=/opt/logstash
command=/opt/logstash/bin/logstash -f /etc/logstash.d/ -w 10 -l /var/log/logstash/pro1.log
service supervisord start
1.2 简述
logstash就像 cat grep awk | 等联合使用,读取–>过滤–>输出
数据在线程之间以 事件 的形式流传。不要叫行,因为 logstash 可以处理多行事件。
- host 标记事件发生在哪里。
- type 标记事件的唯一类型。
- tags 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
- timestamp 时间
1.3 nginx日志搜集示例
1.3.1 openresty配置
安装openresty,简单配置如下:
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"domain":"$host",'
'"url":"$uri",'
'"status":"$status"}';
access_log logs/access.log_json json;
server {
listen 8080;
location / {
default_type text/html;
content_by_lua '
ngx.say("<p>hello, world</p>")
';
}
}
}
启动openresty并访问:
nginx -p `pwd`/ -c conf/nginx.conf
curl http://localhost:8080/
curl结果如下:
<p>hello, world</p>
查看日志:tail logs/access.log_json json
{"@timestamp":"2017-01-03T02:25:09+08:00","@version":"1","host":"127.0.0.1","client":"127.0.0.1","size":31,"responsetime":0.000,"domain":"localhost","url":"/","status":"200"}
1.3.2 logstash 配置
编写配置文件 nginxlog.conf
input {
file {
path => "/usr/local/openresty/work/logs/access.log_json"
codec => "json"
}
}
output {
stdout { codec=> rubydebug }
}
启动logstash
/usr/local/logstash-5.1.1/bin/logstash -f config/nginxlog.conf
启动完成后,再访问nginx(openresty),可以看到logstash标准输出,说明成功:
{
"path" => "/usr/local/openresty/work/logs/access.log_json",
"@timestamp" => 2017-01-02T18:31:27.000Z,
"size" => 31,
"domain" => "127.0.0.1",
"@version" => "1",
"host" => "127.0.0.1",
"client" => "127.0.0.1",
"responsetime" => 0.0,
"url" => "/",
"status" => "200",
"tags" => []
}
二、elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.1 elasticsearch 安装
unzip elasticsearch-5.1.1.zip
./elasticsearch-5.1.1/bin/elasticsearch -d
注意:默认不能root启动
测试启动:
curl 'http://localhost:9200/_search?pretty'
有输出,说明启动成功。也可以在浏览器输入http://localhost:9200/。但注意,如果不是localhost,需要修改config/elasticsearch.yml配置,开启http端口和解除IP限制如:
cluster.name: chuck-cluster # 判别节点是否是统一集群
node.name: linux-node1 #节点的hostname
path.data: /data/es-data #数据存放路径
path.logs: /var/log/elasticsearch/ #日志路径
bootstrap.mlockall: true #锁住内存,使内存不会再swap中使用
network.host: 0.0.0.0 允许访问的ip
http.port: 9200 端口
浏览器输出如下json说明正常:
{
"name": "Lq2kUZ1",
"cluster_name": "elasticsearch",
"cluster_uuid": "u_fJqJnYRduFqasYop5H-w",
"version": {
"number": "5.1.1",
"build_hash": "5395e21",
"build_date": "2016-12-06T12:36:15.409Z",
"build_snapshot": false,
"lucene_version": "6.3.0"
},
"tagline": "You Know, for Search"
}
注意主机系统时间。
2.2 结合logStash
把上面1.7.2提到的nginxlog.conf改成
input {
file {
path => "/usr/local/openresty/work/logs/access.log_json"
codec => "json"
}
}
output {
elasticsearch { hosts => "localhost" }
stdout { codec=> rubydebug }
}
重启logstash作为后台进程:
nohup ./bin/logstash -f config/nginxlog.conf >/dev/null 2>&1 &
此时再访问nginx,相关日志就被搜集到elasticsearch
三、kibana
Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索),您可以使用它。说到搜索,logstash带有一个web界面,搜索和展示所有日志。
3.1 安装
解压启动:./bin/kibana,默认连接elasticsearch。
使用http://localhost:5601访问。如果在其他机器上无法访问,可以通过nginx代理。
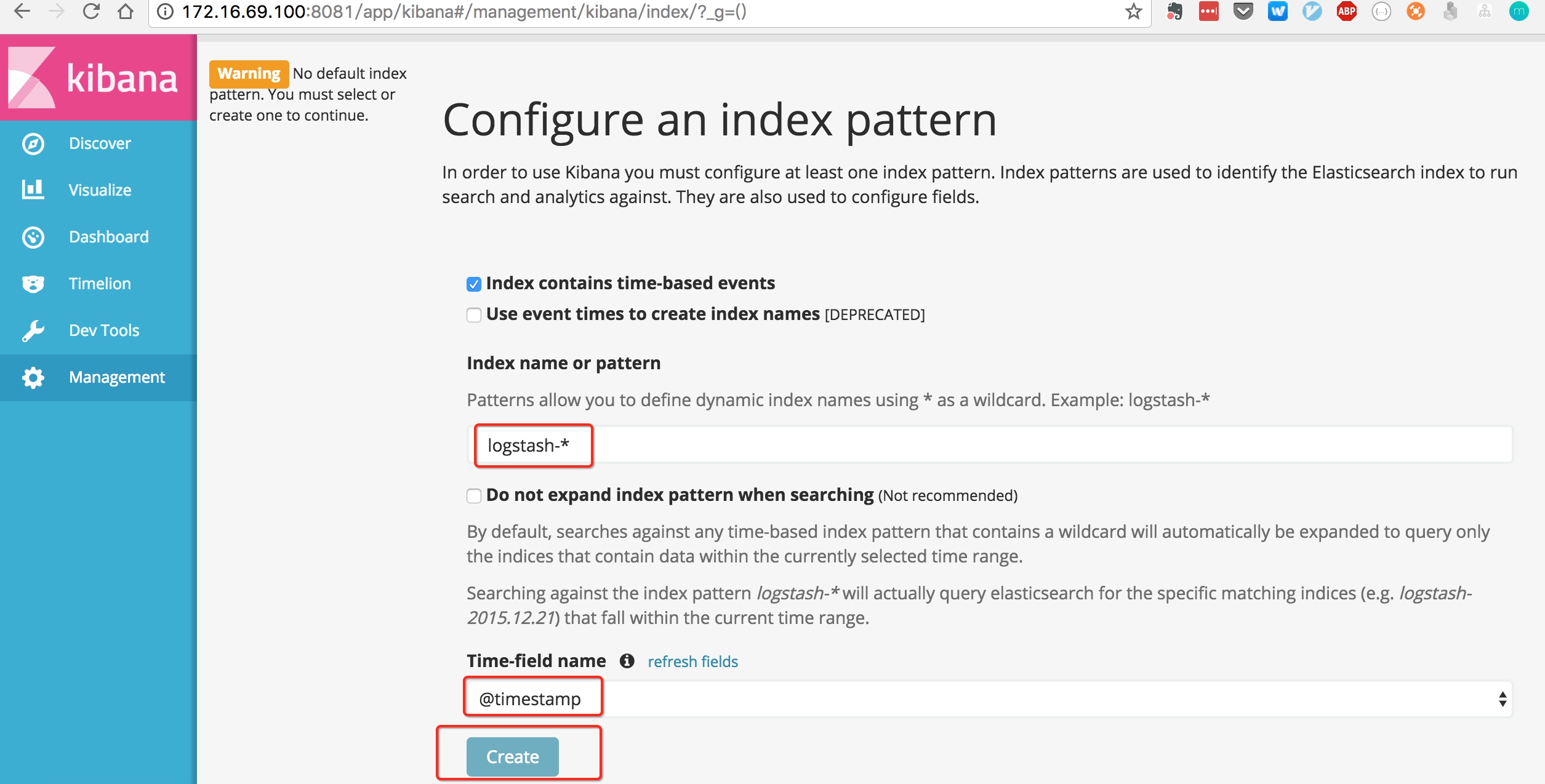
第一次访问,需要创建一个索引类型:
默认使用logstash-*配置index,create完成后,去discover面板即可搜索日志。
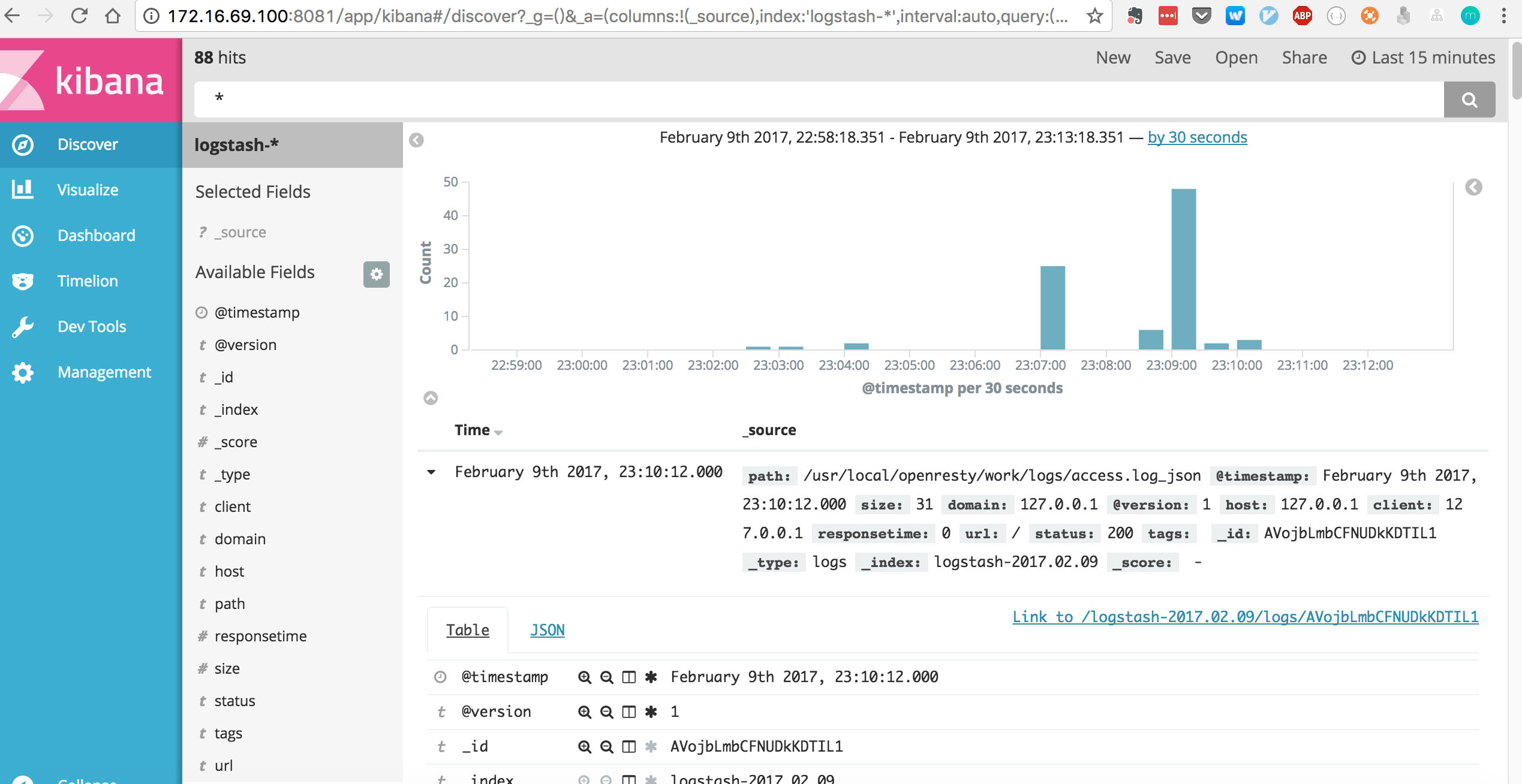
可以看到访问nginx的日志:
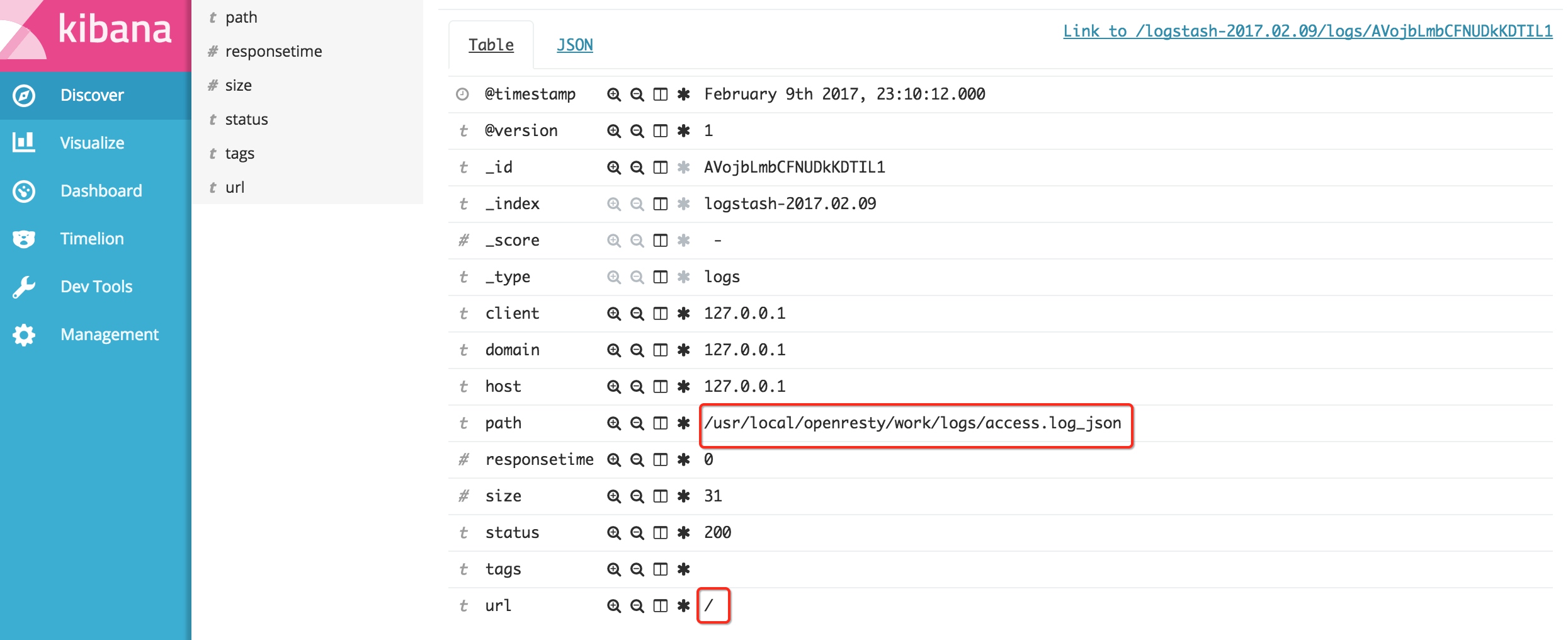
至此,ELK示例安装完成。但如果用到生产环境,日志量大,需要大磁盘大内存的服务器、集群部署、调优才能满足使用。还可以结合redis,kafka等消息队列解耦。