概述
现有一需求,自己实现redis集群。最简单的方式是,把数据分配到不同的redis实例,而同一个key,每次存取都会连接同一个redis实例。
这里面涉及几个问题:故障;扩容;数据均匀分配。下面,我们看一致性hash算法怎么解决这些问题。
简陋实现
现有四台redis:
node1 (192.168.99.101:6379)
node2 (192.168.99.102:6379)
node3 (192.168.99.103:6379)
node4 (192.168.99.104:6379)
实例数量n=4; 如果缓存k,v如:“name”:“thoreau”, 通过hash计算出对应的redis实例:
// hashcode绝对值取模
index = (Math.abs("name".hashCode()) % n)
index =3, 定位到第四台redis,这就是最简单的实现,那它有什么问题呢,我们看一个示例:
AtomicInteger atomicInteger = new AtomicInteger();
@Test
public void testNodeChange() {
int n = 4, newNode = 5;
for (int i = 0; i < 100_0000; i++) {
int r1 = Math.abs(("key" + i).hashCode()) % n;
int r2 = Math.abs(("key" + i).hashCode()) % newNode;
if (r1 != r2) {
atomicInteger.addAndGet(1);
}
}
System.out.println(atomicInteger);
}
输出:800112
也就是说,新增一个节点,100万数据有80万需要迁移到新node,其实很好理解,就是4/5的数据都需要迁移。节点数(redis实例)越多,每加一个节点,数据迁移量越大,给扩容带来很大的麻烦。
hash环
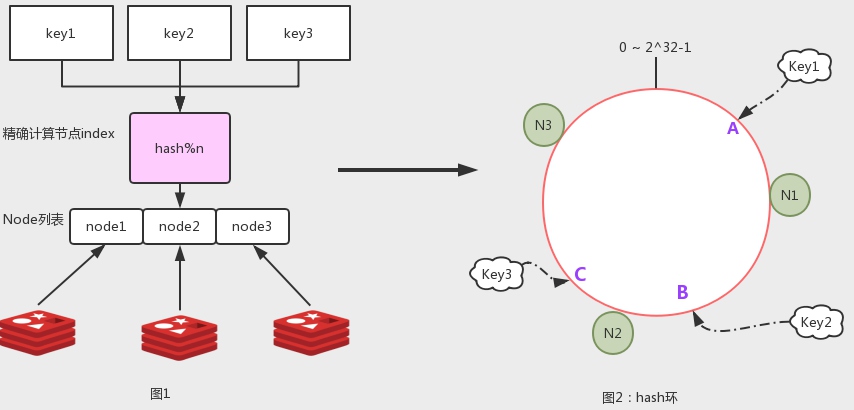 为了解决扩容带来的大数据量迁移的问题,引入hash环。如图2,假设hash值范围是0到2^32-1,首尾连成环,环上分布3个Node。假如key1的hash结果是A,沿环顺时针寻找,找到的第一个节点N1,这个实例就是key的数据落点。
为了解决扩容带来的大数据量迁移的问题,引入hash环。如图2,假设hash值范围是0到2^32-1,首尾连成环,环上分布3个Node。假如key1的hash结果是A,沿环顺时针寻找,找到的第一个节点N1,这个实例就是key的数据落点。
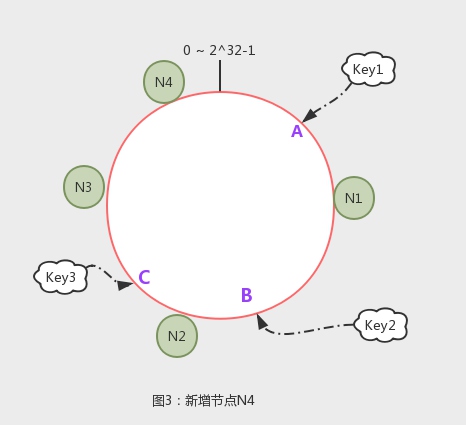
优点: 如果新增一个节点,那么,需要迁移的数据只有hash值处于新节点和逆时针方向第一个节点间的范围。如图3,新增N4,那么,只有N3到N4间的数据受影响,解决了取模运算方式大量数据迁移的麻烦。
Java实现:
/**
* 物理节点接口
*/
public interface PhysicalNode {
/**
* 返回用于计算hash的key
*/
String getKey();
}
/**
* hash算法接口
*/
public interface IHash {
/**
* 根据字符串key,获取long型hash值
*/
long getHash(String key);
}
public class ConsistentHash {
private SortedMap<Long, PhysicalNode> hashWheel = new TreeMap<>();
private IHash hashfunc = new MD5Hash();
public void addNode(PhysicalNode physicalNode) {
long hash = hashfunc.getHash(physicalNode.getKey());
hashWheel.put(hash, physicalNode);
}
public PhysicalNode getNode(String key) {
long hash = hashfunc.getHash(key);
SortedMap<Long, PhysicalNode> collect = hashWheel.tailMap(hash);
return hashWheel.get(collect.firstKey());
}
}
hash算法可以选择(FNV1_32_HASH, MD5, crc32,….),实现IHash的getHash方法。 hash轮使用treeMap存储:
- treeMap基于红黑树实现,查找时间复杂度O(logN)
- 提供tailMap(K fromKey),返回fromKey之后的map。正好适用hash环顺时针查找。
测试一下:
@Test
public void testNode() {
List<PhysicalNode> redisNodes = new ArrayList<>();
IHash hash = new MD5Hash();
redisNodes.add(new RedisNode("192.168.99.100", 8080));
redisNodes.add(new RedisNode("192.168.99.101", 8080));
redisNodes.add(new RedisNode("192.168.99.102", 8080));
redisNodes.add(new RedisNode("192.168.99.103", 8080));
ConsistentHash consistentHash = new ConsistentHash(redisNodes);
String key1 = "hello";
String key2 = "world";
String key3 = "1";
String key4 = "pwdpwdpwdpwdpwd";
log.info("key:{}, hash:{}, node:{}", key1, hash.getHash(key1), consistentHash.getNode(key1));
log.info("key:{}, hash:{}, node:{}", key2, hash.getHash(key2), consistentHash.getNode(key2));
log.info("key:{}, hash:{}, node:{}", key3, hash.getHash(key3), consistentHash.getNode(key3));
log.info("key:{}, hash:{}, node:{}", key4, hash.getHash(key4), consistentHash.getNode(key4));
}
格式输出:
add node[192.168.99.100:8080],hash:[1546744927] add node[192.168.99.101:8080],hash:[3621727994] add node[192.168.99.102:8080],hash:[426906814] add node[192.168.99.103:8080],hash:[4138500944]
key:hello, hash:1564557354, node:192.168.99.101:8080 key:world, hash:2105094199, node:192.168.99.101:8080 key:1, hash:3301589560, node:192.168.99.101:8080 key:pwdpwdpwdpwdpwd, hash:37046274, node:192.168.99.102:8080
可以看到,4台redis的ip+端口进行hash,值从小到大依次是:1546744927(node1) -> 3621727994 (node2)-> 4138500944(node4) ->426906814(node3)。 四个key有3个的hash值在node1和node2之间,所以对于节点是node2。
如果新增一个节点192.168.99.104:8080,hash值:2941049386,相当于在node1和node2直接新增节点,node1和新增节点间的数据需要迁移。
这样,一个简单的hash环实现了一致性hash算法。但从示例中也看得出来,数据分布不不均匀。要解决这个问题,需要引入虚拟节点。
虚拟节点
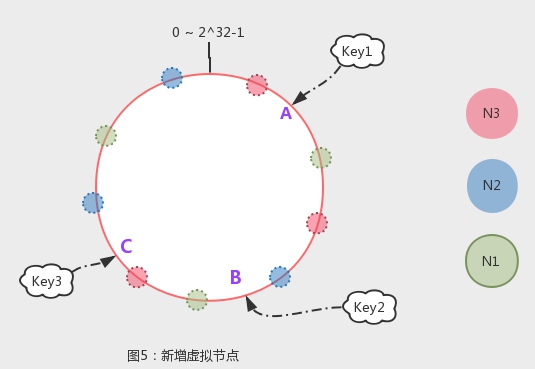
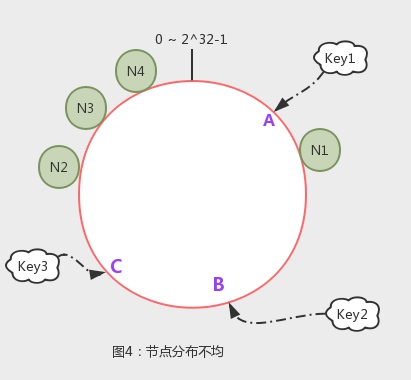 如上图,如果物理节点N1-N4的hash值比较集中在一个小范围,将会导致,N1到N2之间的所有数据将被分配到N2节点。我们引入虚拟节点,每个物理节点管理一定数量的虚拟节点,虚拟节点分布在环上,和物理节点有映射。如下图,通过引入虚拟节点,环上的小球归属同颜色的N1-N3,一个物理节点存0~ 2^32-1范围内多个片段的数据,从而是分配更均匀,也没破坏迁移成本。
如上图,如果物理节点N1-N4的hash值比较集中在一个小范围,将会导致,N1到N2之间的所有数据将被分配到N2节点。我们引入虚拟节点,每个物理节点管理一定数量的虚拟节点,虚拟节点分布在环上,和物理节点有映射。如下图,通过引入虚拟节点,环上的小球归属同颜色的N1-N3,一个物理节点存0~ 2^32-1范围内多个片段的数据,从而是分配更均匀,也没破坏迁移成本。
 java 实现:
java 实现:
@Getter
public class VirtualNode {
/**
* 虚拟节点序号
*/
private int replicaNumber;
/**
* 对应的物理节点
*/
private PhysicalNode parent;
public VirtualNode(PhysicalNode parent, int replicaNumber) {
this.replicaNumber = replicaNumber;
this.parent = parent;
}
/**
* 使用物理节点的"key#12"作为虚拟节点的key
*
* @return String
*/
public String getKey() {
return parent.getKey() + "#" + replicaNumber;
}
}
具体实现:
@Slf4j
public class ConsistentHash {
/**
* hash 轮使用treeMap存储:
* <p>
* 1. treeMap基于红黑树实现,查找时间复杂度O(logN)
* 2. 提供tailMap(K fromKey),返回fromKey之后的map。正好和hash环顺时针查找切和
*/
private SortedMap<Long, VirtualNode> hashWheel = new TreeMap<>();
/**
* 默认虚拟节点数
*/
private final static int DEFAULT_VNODE_SIZE = 150;
/**
* md5实现hash
*/
private IHash hashfunc = new MD5Hash();
/**
* 初始化节点
*
* @param servers
*/
public ConsistentHash(Collection<PhysicalNode> servers) {
for (PhysicalNode server : servers) {
addNode(server);
}
}
/**
* 添加节点
*
* @param physicalNode 节点
*/
public void addNode(PhysicalNode physicalNode) {
// 获取虚拟节点序号
int virtualNumber = getVirtualNumber(physicalNode.getKey());
for (int i = 0; i < DEFAULT_VNODE_SIZE; i++) {
VirtualNode virtualNode = new VirtualNode(physicalNode, virtualNumber + i);
// 对虚拟节点key计算hash值
long hash = hashfunc.getHash(virtualNode.getKey());
hashWheel.put(hash, virtualNode);
}
log.info("add node[{}],hash:[{}]", physicalNode.getKey());
}
/**
* 获取节点
*
* @param key key
* @return 节点信息
*/
public PhysicalNode getNode(String key) {
long hash = hashfunc.getHash(key);
SortedMap<Long, VirtualNode> collect = hashWheel.tailMap(hash);
if (collect.size() == 0) {
return hashWheel.get(hashWheel.firstKey()).getParent();
}
return hashWheel.get(collect.firstKey()).getParent();
}
/**
* parentKey#number
*
* @param nodeKey nodeKey
* @return number
*/
private int getVirtualNumber(String nodeKey) {
int num = 0;
for (VirtualNode node : hashWheel.values()) {
if (node.getKey().equals(nodeKey)) {
num++;
}
}
return num;
}
}
测试hash分布:
Map<String, AtomicInteger> count = new HashMap<>();
@Test
public void testBalance() {
List<PhysicalNode> redisNodes = new ArrayList<>();
IHash hash = new MD5Hash();
redisNodes.add(new RedisNode("192.168.99.100", 8080));
redisNodes.add(new RedisNode("192.168.99.101", 8080));
redisNodes.add(new RedisNode("192.168.99.102", 8080));
redisNodes.add(new RedisNode("192.168.99.103", 8080));
ConsistentHash consistentHash = new ConsistentHash(redisNodes);
for (int i = 0; i < 1000000; i++) {
addCount(consistentHash.getNode("key" + i));
}
System.out.println(count);
}
private void addCount(PhysicalNode node) {
if (count.get(node.getKey()) == null) {
count.put(node.getKey(), new AtomicInteger(1));
} else {
count.get(node.getKey()).addAndGet(1);
}
}
输出 {192.168.99.101:8080=267981, 192.168.99.103:8080=248429, 192.168.99.102:8080=227529, 192.168.99.100:8080=256061}
测试结果显示,100万数据,每个节点有25万左右,相对均匀。这样,一致性hash算法的实现就算完成了。
参考: [1]. 一致性哈希算法的理解与实践/ [2]. 对一致性Hash算法,Java代码实现的深入研究 [3]. Hash 函数概览 [4]. 陌生但默默一统江湖的MurmurHash