Sentinel作用
Sentinelm,分布式系统的流量防卫兵,可以从多个维度保护应用,广泛用于阿里各个系统,是大促稳定性保障的关键。现已开源,github地址Sentinel。
最常用的场景就是限流,比方说提供某个http接口的服务,经过压测,我单机qps只能达到500,流量再大就可能导致系统崩溃,从而无法提供服务。参考压测进过,可以对此接口限流500,一旦超过,其他请求就快速失败,从而保证系统正常工作不被压垮。sentinel总结起来主要有以下作用:
- 保护服务提供方不被过于频繁的调用压垮。
- 保护服务调用方不被不可用的服务拖死。
- 保护系统不超过负载。
Sentinel 的开源生态:

图1: 来源:sentinel github wiki
qps限流示例
下文通过一个示例,见github下sentinel-demo/sentinel-demo-basic。其他如spring的整合见spring-cloud-starter-alibaba-sentinel文档
static class RunTask implements Runnable {
@Override
public void run() {
while (!stop) {
Entry entry = null;
try {
// 1.获取token,如果不能,将会抛出BlockException
entry = SphU.entry(KEY);
pass.addAndGet(1);
} catch (BlockException e1) {
block.incrementAndGet();
} catch (Exception e2) {
// biz exception
} finally {
total.incrementAndGet();
if (entry != null) {
// 2. 退出
entry.exit();
}
}
Random random2 = new Random();
try {
TimeUnit.MILLISECONDS.sleep(random2.nextInt(50));
} catch (InterruptedException e) {
}
}
}
}
上面只是截取了FlowQpsDemo的一段代码,这个示例主要做了几个工作:
- 初始化限流规则,限流20
- 开启32个线程循环执行RunTask,并把总qps/通过qps/限流qps分表计入3个AtomicInteger
- 开启一个定时任务,每秒统计一次3个AtomicInteger的值,作为统计数据输出
如:
1541907654105, total:1185, pass:20, block:1165
46 send qps is: 1218
1541907655110, total:1218, pass:21, block:1197
45 send qps is: 1130
1541907656115, total:1130, pass:20, block:1110
44 send qps is: 1177
1541907657119, total:1177, pass:22, block:1155
出现大于20的情况,因为统计线程有误差。那么,sentinel之所以能限流,肯定也统计了qps,有误差么?这个问题以后讨论
概念名词解释
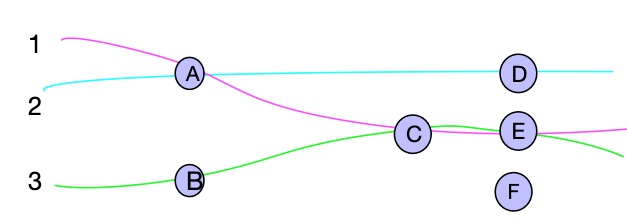
图2
可以理解,上图为一个应用,其中ABCDEF为可以对其授权、限流、降级的入口,在sentinel中也叫切入点。比如现在访问C的qps为100,但是有可能A->C的访问频繁但不是很重要,而B-C次数不多但比较关键。此时我只想对A->C限流,于是就需要一个链路的概念,途中1、2、3组成3条链路,链路上的切入点也叫树节点。这些切入点可能处于不同链路如C,于是把用来汇总切入点信息的叫簇结点。
示最简单的示例中,sentinel入口代码,定义一个切入口。
// 为需要保护的资源(概念或者逻辑上)定义一个入口,所有访问资源的请求都需要从此入口申请令牌
Entry entry = SphU.entry(“自定义资源名”);
如果要把节点纳入链路中,需要根据链路限流,需要通过上下文(Context)声明链路入口如:
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
原理
还是从示例FlowQpsDemo,进入entry = SphU.entry(KEY)代码开始分析;
// 为了获取令牌,从此入口进入,通过一些列ProcessorSlot校验限流规则,能通过返回Entry,否则抛BlockException
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
Context context = ContextUtil.getContext();
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
if (context == null) {
// Using default context.
context = MyContextUtil.myEnter(Constants.CONTEXT_DEFAULT_NAME, "", resourceWrapper.getType());
}
// 2
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
/*
* Means amount of resources (slot chain) exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE},
* so no rule checking will be done.
*/
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
chain.entry(context, resourceWrapper, null, count, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
- 从threadLocal获取Context,没有就使用默认Context
- 获取处理Slot(ProcessorSlot)
- 执行Slot的entry方法,校验通过则返回Entry
整个设计模式和netty类似:
| 责任链模式 | netty | sentinel | ||
|---|---|---|---|---|
| 链 | ChannelPipeline | chain | ||
| 处理器 | ChannelHandler | ProcessorSlot | ||
| 上下文,携带元数据 | ChannelHandlerContext | Context | ||
| 不同 | 双向链表 | 单向链表 |
所以下文重点看采用了哪些ProcessorSlot。
ProcessorSlot
先看lookProcessChain是如何创建ProcessorSlotChain。
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
// 更加资源wrapper从缓存查询
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
// 缓存不存在,加锁双重检查创建chain
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
chain = SlotChainProvider.newSlotChain();
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}
我们接着看chain = SlotChainProvider.newSlotChain()如何创建chain,跟踪代码发现DefaultSlotChainBuilder这个类,build方法如下。
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new LogSlot());
chain.addLast(new StatisticSlot());
chain.addLast(new SystemSlot());
chain.addLast(new AuthoritySlot());
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
return chain;
}
- NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
- ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
- StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;
- FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;
- AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;
- DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;
- SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
总体框架图:

图3

图4: 3/4来源:sentinel github wiki
下午详细看看几个slot。
NodeSelectorSlot
从上文可知,NodeSelectorSlot对象是根据resourceWrapper缓存,也就是说,图2中BC节点(资源/入口)分别拥有不同NodeSelectorSlot对象。NodeSelectorSlot缓存了对应节点DefaultNode。
但是,缓存DefaultNode的key不是资源名,因为同一个资源可能处于不同链路,所以,sentinel采用Context的名字来缓存DefaultNode,从而构建不同链路的节点树;
图3中treenode还有一种结构没有画出来:
* machine-root
* / \
* / \
* EntranceNode1 EntranceNode2
* / \
* / \
* DefaultNode(nodeA) DefaultNode(nodeA)
* | |
* +- - - - - - - - - - +- - - - - - -> ClusterNode(nodeA);
图5
ClusterBuilderSlot
ClusterBuilderSlot用来创建构建资源的ClusterNode,主要维护资源的运行时统计数据,比如响应时间、qps、线程数、异常等。一个资源有一个clusterNode,但可以有多个defaultNode,如上图5。
StatisticSlot
StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据,维护到NodeSelectorSlot和ClusterBuilderSlot创建的数据结构中:
- clusterNode:资源唯一标识的 ClusterNode 的 runtime 统计
- origin:根据来自不同调用者的统计信息
- defaultnode: 根据上下文条目名称和资源 ID 的 runtime 统计
- 入口的统计
核心代码:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, Object... args)
throws Throwable {
try {
fireEntry(context, resourceWrapper, node, count, args);
// 线程+1
node.increaseThreadNum();
// 通过请求数+1
node.addPassRequest();
if (context.getCurEntry().getOriginNode() != null) {
// 如果origin不为空,也更新数据
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest();
}
if (resourceWrapper.getType() == EntryType.IN) {
// ru入站请求,全局统计
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest();
}
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
context.getCurEntry().setError(e);
// Add block count.
node.increaseBlockQps();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps();
}
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseBlockQps();
}
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
context.getCurEntry().setError(e);
// Should not happen
node.increaseExceptionQps();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps();
}
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps();
}
throw e;
}
}
我们关注下这两行代码:
node.increaseThreadNum();
node.addPassRequest();
线程数统计比较容器,AtomicInteger保存即可。但是qps怎么统计,毕竟qps是一段时间内的请求数量。 我们找到如下代码:
@Override
public void addPassRequest() {
rollingCounterInSecond.addPass();
rollingCounterInMinute.addPass();
}
在深入看代码之前,我们先看看,假设统计qps,我们会怎么做。比如用一个AtomicInteger数组保存每一秒的请求,index就是当前秒/60。 统计qps只需要用当前时间计算数组Index,就可以获取qps。比如下图,1时秒10qps,2秒时400qps。
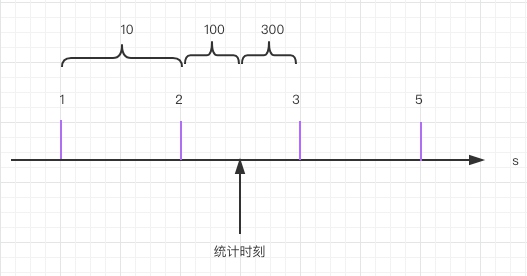
图6
问题在于:读取qps的时间不是整秒,比如上图,统计时刻2秒500毫秒,此时,获取的qps是100,但其实还有后500毫秒的请求没有统计。如果此时我统计t-1呢,也就是1秒的qps,此刻qps是准确的,但是不及时,第2秒的qps突然暴增,那统计就延迟了一秒。对只用来展示倒是问题不太大,但是对于限流来说,晚1秒可能系统已经挂了。
优化的办法,我们会想,把时间间隔缩小,比如10ms。这样是更准确了,但是就得保存很多数据,并且求qps需要把100个刻度加起来。对资源消耗太大。下面,我们看看sentinel怎么做的。
sentinel使用滑动窗口,数据结构如下:
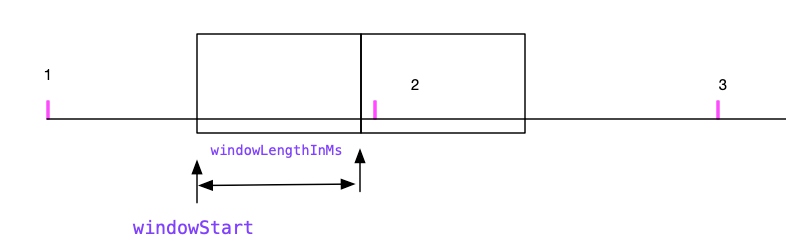
图7
public class WindowWrap<T> {
/**
* 一个bucket的长度,单位毫秒
*/
private final long windowLengthInMs;
/**
* 窗口开始时间,也是毫秒
*/
private long windowStart;
/**
* 统计值
*/
private T value;
}
sentinel 默认采用windowLengthInMs=500计算qps。也就是说,1秒只有两个窗口。初始化如下方式如下
// 1. 创建rollingCounterInSecond
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(1000 / SampleCountProperty.SAMPLE_COUNT,1)
ArrayMetric{
// 2. ArrayMetric包装了 MetricsLeapArray
private final MetricsLeapArray data = new MetricsLeapArray(500, 1);
}
public abstract class LeapArray<T> {
// 3 array 所以计算qps ,sampleCount = 2。
protected final AtomicReferenceArray<WindowWrap<T>> array = new AtomicReferenceArray<WindowWrap<T>>(sampleCount);
}
创建几个bucket,取决于SampleCountProperty.SAMPLE_COUNT设置。还有个rollingCounterInMinute用于存储分钟请求数,buckets长度是1000ms。
累积请求
主要是以下步骤:
- 获取当前窗口(bucket)
- bucket的值+1
获取当前窗口(bucket)
- 获取当前时间
- 计算当前时间对应的bucket下标(index)和bucket起始时间。
- 获取窗口 array.get(index),
public WindowWrap<T> currentWindow(long time) {
long timeId = time / windowLengthInMs;
// Calculate current index.
int idx = (int)(timeId % array.length());
// Cut the time to current window start.
time = time - time % windowLengthInMs;
while (true) {
WindowWrap<T> old = array.get(idx);
if (old == null) {
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, time, newEmptyBucket());
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
Thread.yield();
}
} else if (time == old.windowStart()) {
return old;
} else if (time > old.windowStart()) {
if (updateLock.tryLock()) {
try {
// if (old is deprecated) then [LOCK] resetTo currentTime.
return resetWindowTo(old, time);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
} else if (time < old.windowStart()) {
// Cannot go through here.
return new WindowWrap<T>(windowLengthInMs, time, newEmptyBucket());
}
}
}
1. 如果为空就新创建一个,new WindowWrap<T>
2. 如果不为空,且窗口时间对得上,则使用这个窗口
3. 如果时间大于返回窗口的起始时间,说明这个窗口过期,应该加锁重置为新窗口
4. 如果窗口时间小于返回窗口的起始时间,也不能用,也需要新返回一个bucket
// add pass(LongAdder)
wrap.value().addPass();
MetricBucket{
// 使用LongAdder保存数据,高并发下比cas原子操作类性能更好
private final LongAdder pass = new LongAdder();
}
获取qps
qps就是通过的请求,统计pass只需要把所有bucket的请求相加,StatisticNode代码如下:
@Override
public long pass() {
data.currentWindow();
long pass = 0;
List<MetricBucket> list = data.values();
for (MetricBucket window : list) {
pass += window.pass();
}
return pass;
}
qps统计只用了两个buckets,其实也跟我们最初设计的有一样的问题,如果流量波动加大,还是反应慢,可以适当调整bucket数量,比如10个。
SystemSlot
按系统负载级别限流。只按照一个切入口qps,可能并不能反映系统负责情况。还可能需要考虑所有线程、qps、rt,load等。
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, Object... args)
throws Throwable {
SystemRuleManager.checkSystem(resourceWrapper);
fireEntry(context, resourceWrapper, node, count, args);
}
public static void checkSystem(ResourceWrapper resourceWrapper) throws BlockException {
// Ensure the checking switch is on.
if (!checkSystemStatus.get()) {
return;
}
// for inbound traffic only
if (resourceWrapper.getType() != EntryType.IN) {
return;
}
// total qps
double currentQps = Constants.ENTRY_NODE == null ? 0.0 : Constants.ENTRY_NODE.successQps();
if (currentQps > qps) {
throw new SystemBlockException(resourceWrapper.getName(), "qps");
}
// total thread
int currentThread = Constants.ENTRY_NODE == null ? 0 : Constants.ENTRY_NODE.curThreadNum();
if (currentThread > maxThread) {
throw new SystemBlockException(resourceWrapper.getName(), "thread");
}
double rt = Constants.ENTRY_NODE == null ? 0 : Constants.ENTRY_NODE.avgRt();
if (rt > maxRt) {
throw new SystemBlockException(resourceWrapper.getName(), "rt");
}
// BBR algorithm.
if (highestSystemLoadIsSet && getCurrentSystemAvgLoad() > highestSystemLoad) {
if (currentThread > 1 &&
currentThread > Constants.ENTRY_NODE.maxSuccessQps() * Constants.ENTRY_NODE.minRt() / 1000) {
throw new SystemBlockException(resourceWrapper.getName(), "load");
}
}
}
比较好理解,只是多了一个load的实时统计。这里使用一个算法BBR 来实现。
总结
本文简单介绍sentinel的责任链模式完成限流,并介绍了几个slot。其实还有很多细节可以挖掘。
参考: