Spring Cloud 分布式系统追踪
微服务的特点就是服务多,依赖关系复杂。一个请求进来,整个调用链是什么样的,各个服务的调用时间,错误出现在哪个服务、哪台机器上等等问题。如果没有贯穿前后的调用链,很难定位问题。
Spring Cloud 系统提供 sleuth + zipkin 的整合方式解决这个问题。下面先从一个示例开始。
在服务中使用sleuth
在spring cloud中使用很简单,依赖spring-cloud-starter-sleuth即可,如果需要导出到zikip,根据选择http还是mq方式另加包。
maven 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
- spring-cloud-starter-sleuth : 添加这个包,就可以在日志中打印出traceId和spanId。如果不要使用zipkin做分析,这个包就可以了。
- spring-cloud-sleuth-stream 和 spring-cloud-stream-binder-rabbit :通过stream把元信息通过mq发送给使用方(zipkin)。如果不使用zipkin,这俩包不需要。
在微服务中引入以上依赖,spring cloud微服务日志如下:
2017-04-11 22:50:10.365 INFO [cloud-api-gateway,1c6ffcbf0c03cd09,1c6ffcbf0c03cd09,false] 15563 --- [nio-9006-exec-8] c.e.s.gateway.filter.AccessFilter : request method:GET, request url: http://localhost:9006/trade/order
2017-04-11 22:50:10.545 INFO [cloud-service-trade,1c6ffcbf0c03cd09,5dcbb6e53fa2c2e5,false] 15715 --- [nio-9007-exec-1] c.e.springcloud.trade.web.OrderResouce : gateway call me
日志日别(INFO)后的[]中四个data很关键,第一个服务名(对应spring.application.name),第二个是traceId,第三个是spanId,第四个标注sleuth元信息是否导出(mq等)。对traceId和spanId,span生命周期等不做介绍,详细信息请看sleuth github。
简单说,一个请求,不管经过几次调用调用几个服务,所有traceId都一样。可以在gateway(ZUUL)中,把traceId放到HTTP的restpose header,如果请求有问题,通过header拿到traceId,就可以到日志文件或者ELK搜索相应日志信息。
Logstash fileter配置如下:
input {
file {
type => "spring-cloud"
path => "/tmp/cloud.log"
codec => multiline {
pattern => "^\d{4}-\d{2}-\d{2}"
negate => true
what => "previous"
}
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}"
}
}
}
output {
stdout { codec=> rubydebug }
elasticsearch { hosts => "localhost" }
}
Kibana展示:
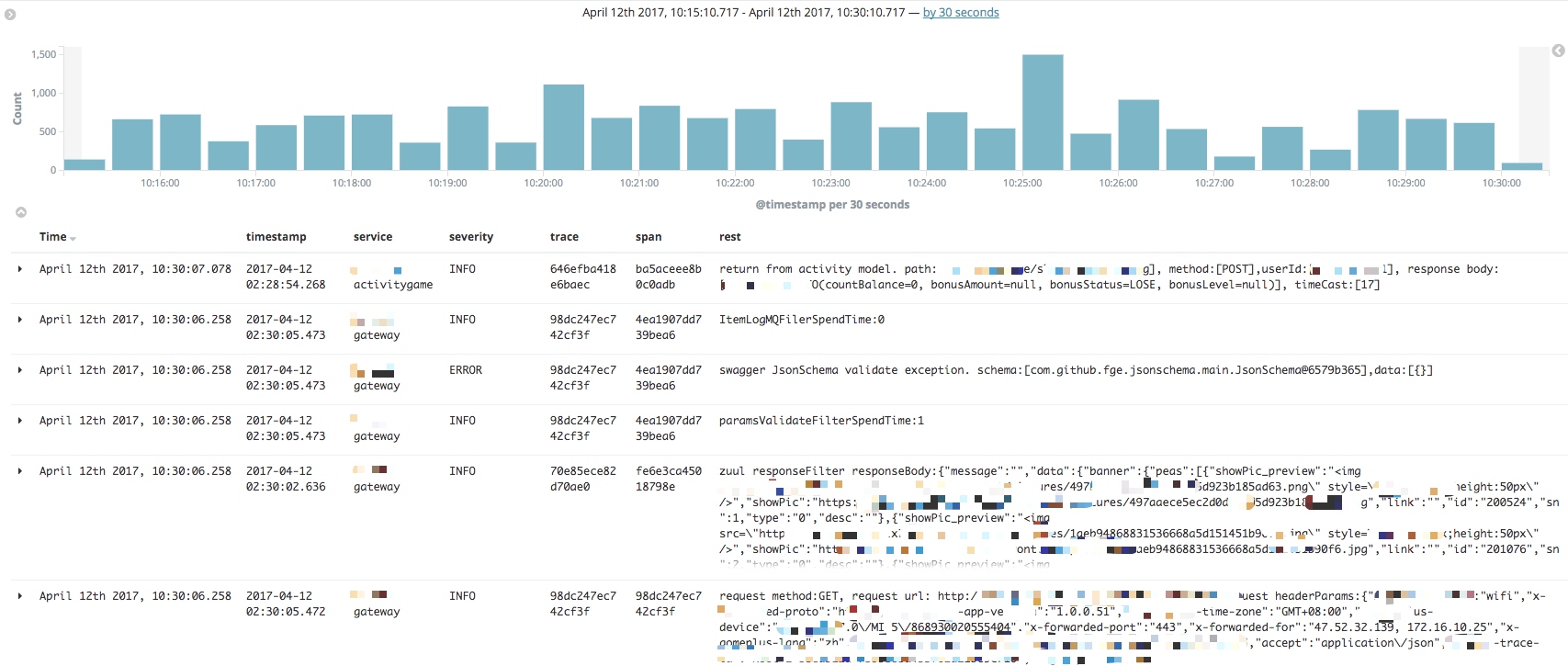
部分敏感信息马赛克了,EKL安装见我的另一篇博客ELK日志搜集查询
结合Zipkin展示
1.mavem依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
2. 启动函数
@SpringBootApplication
@EnableDiscoveryClient
@EnableZipkinStreamServer
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
配置消费mq中的sleuth信息。格式如下:
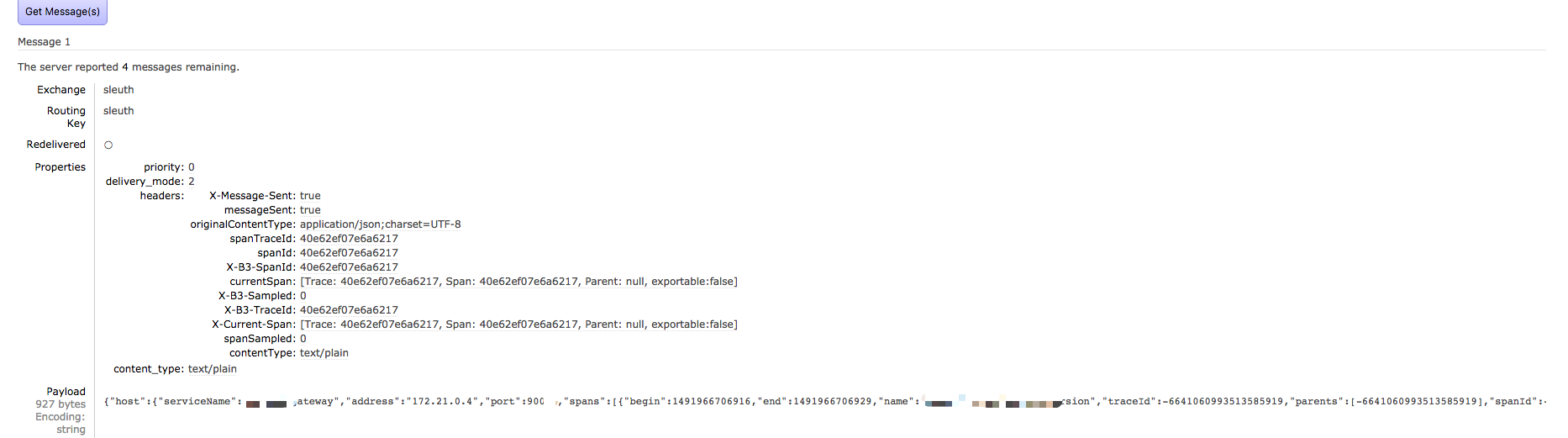
注意: 默认情况下,并不是每一条都导出到mq中,只有10%,如果测试时想得到结果,可以把
spring.sleuth.sampler.percentage配置为1.0,也可以通过定义bean的方式覆盖默认配置。
zikin UI 展示:
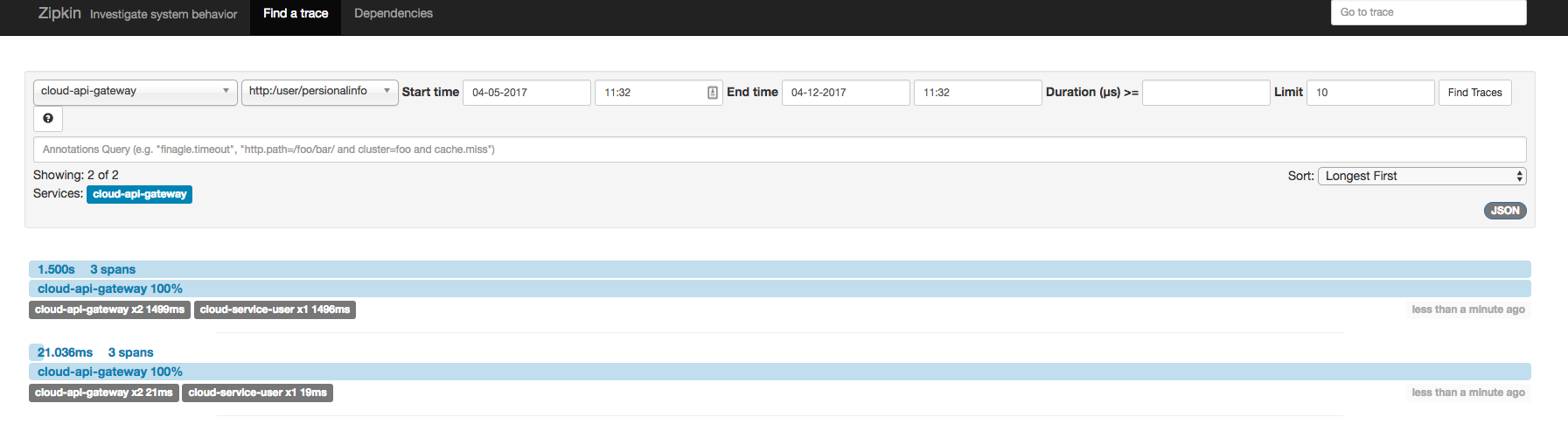
可以从查看整个调用链每个节点上用了多次时间,是否保存等信息,还可以分析出微服务依赖图,如下:
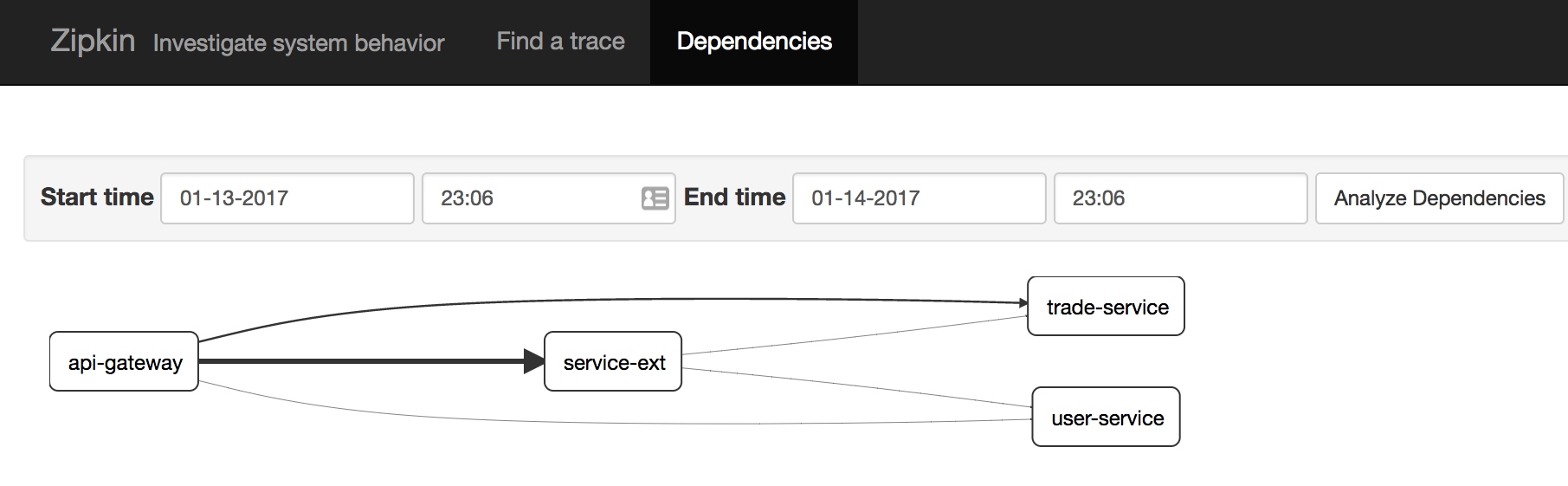
默认zipkin把消费的信息存入内存,如果用到开发环境中,应改存储为mysql或者Elasticsearch等。下面介绍mysql示例:
<!--mysql-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-mysql</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
bootstrp.yaml配置:
spring:
profiles: dev
datasource:
schema: classpath:/mysql.sql
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.99.100:3306/zipkin
username: root
password: 1234
initialize: true
continueOnError: true
sleuth:
enabled: false
zipkin:
storage:
type: mysql
初始化数据库脚本可以从github获取: oopenzipkin
使用Elasticsearch Storage 配置也差不多,但得配合Spark job 才能出依赖关系图zipkin-dependencies
Sleuth原理
sleuth 实现原理,简单说就是通过拦截器(Filter)处理http请求头信息,把需要日志打印的信息放入slf4j.MDC,logback获取相应信息输出到文件或控制台等(不建议直接从logback通过网络导出lagstash、kafka等)。
过滤器
下面看下最重要的过滤器: TraceFilter
@Order(TraceFilter.ORDER)//@Order(-2147483643)
public class TraceFilter extends GenericFilterBean {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
if (!(servletRequest instanceof HttpServletRequest) || !(servletResponse instanceof HttpServletResponse)) {
throw new ServletException("Filter just supports HTTP requests");
}
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String uri = this.urlPathHelper.getPathWithinApplication(request);
// 如果请求访问静态页面、图片、health、swargger等资源是,跳过
// 如果请求或者返回Header中有X-B3-Sampled,跳过
boolean skip = this.skipPattern.matcher(uri).matches()
|| Span.SPAN_NOT_SAMPLED.equals(ServletUtils.getHeader(request, response, Span.SAMPLED_NAME));
// 获取请求体中的spanId
Span spanFromRequest = getSpanFromAttribute(request);
if (spanFromRequest != null) {
// 如果spanId 不为空,沿用此ID
continueSpan(request, spanFromRequest);
}
if (log.isDebugEnabled()) {
log.debug("Received a request to uri [" + uri + "] that should not be sampled [" + skip + "]");
}
// 如果出现异常,关闭span
if (!httpStatusSuccessful(response) && isSpanContinued(request)) {
Span parentSpan = parentSpan(spanFromRequest);
processErrorRequest(filterChain, request, new TraceHttpServletResponse(response, parentSpan), spanFromRequest);
return;
}
String name = HTTP_COMPONENT + ":" + uri;
Throwable exception = null;
try {
// 给request创建span,以过滤器的类名+.TRACE 作为属性名放入request attribute
/* span
name=http:+url
spanId=随机数生成器序列的均匀分布的long值,转换为16进制
traceId=随机数生成器序列的均匀分布的long值,最顶层和spanId一致
logEvent= 时间戳+span的生命周期(sr,ss,cs)
*/
spanFromRequest = createSpan(request, skip, spanFromRequest, name);
filterChain.doFilter(request, new TraceHttpServletResponse(response, spanFromRequest));
} catch (Throwable e) {
exception = e;
// 出现异常,在trace中添加error标记
this.tracer.addTag(Span.SPAN_ERROR_TAG_NAME, ExceptionUtils.getExceptionMessage(e));
throw e;
} finally {
if (isAsyncStarted(request) || request.isAsyncStarted()) {
if (log.isDebugEnabled()) {
log.debug("The span " + spanFromRequest + " will get detached by a HandleInterceptor");
}
return;
}
spanFromRequest = createSpanIfRequestNotHandled(request, spanFromRequest, name, skip);
detachOrCloseSpans(request, response, spanFromRequest, exception);
}
}
}
对于ZUll网关,它有两个filter:TracePreZuulFilter,TracePostZuulFilter。分别在路由前后生成一个span和结束一个span。
2017-04-11 23:40:20.685 DEBUG [cloud-api-gateway,,,] 15747 --- [nio-9006-exec-8] o.s.c.sleuth.instrument.web.TraceFilter : Received a request to uri [/trade/order] that should not be sampled [false]
2017-04-11 23:36:12.754 DEBUG [cloud-api-gateway,f2be362bff25eecb,f2be362bff25eecb,false] 15747 --- [nio-9006-exec-6] o.s.c.sleuth.instrument.web.TraceFilter : No parent span present - creating a new span
日志
默认情况下,默认logging.pattern.level 设置%5p,[${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}], 使用Logback + SLF4J不需要任何配置。
如果想定制自己的日志输出格式,可以在logback-spring.xml文件中覆写log pattern:
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>